Research Ingestion
Feed research papers into Remind and use consolidation to find commonalities, contradictions, and themes across sources. Instead of reading each paper in isolation, Remind builds a connected knowledge graph across all of them.
The problem
You read 10 papers on a topic. Each one has insights, but finding the threads that connect them — the agreements, the contradictions, the gaps — requires holding all of them in your head simultaneously. That's exactly what consolidation is for.
Setup
Create a project for the research topic:
mkdir ~/research/llm-memory
cd ~/research/llm-memory
remind skill-installOptionally create a topic so you can group this survey and scope recall later. Topics are explicit: Remind does not infer or auto-assign them. If you omit a topic, episodes stay untagged (topic_id unset). If you pass --topic to remember or ingest, that name must match an existing topic (create it first).
remind topics create "LLM memory survey" --description "Papers on agent memory architectures"Episode types (the types Remind understands for classification and consolidation):
observation— default for factual summaries and findings from a paperdecision— when you record a methodological or interpretive choicequestion— open research questions or gapsmeta— notes about the reading process, comparisons, or survey structurepreference— stance or weighting (e.g. favoring one design over another)outcome— result of an experiment or evaluation described in the paperfact— specific numbers, claims, or definitions that should stay verbatim in concepts
Walkthrough
Ingesting papers
For each paper, have the agent read it and store key findings as episodes. Add --topic with your topic id or name when you want episodes grouped (optional).
# Paper 1: "Generative Agents" (Park et al.)
remind remember "Generative Agents uses a retrieval-based memory with recency, \
importance, and relevance scoring. Agents reflect on memories to form \
higher-level abstractions." \
-t observation -e person:park -e concept:memory-architecture \
--topic "llm-memory-survey"
remind remember "Generative Agents reflection mechanism: periodically ask \
'what are the most salient high-level questions?' and generate insights" \
-t observation -e concept:reflection -e concept:generative-agents \
--topic "llm-memory-survey"
# Paper 2: "MemGPT" (Packer et al.)
remind remember "MemGPT treats context window as 'working memory' and uses \
explicit read/write to a larger 'archival memory'. Inspired by OS virtual \
memory paging." \
-t observation -e person:packer -e concept:memory-architecture \
--topic "llm-memory-survey"
remind remember "MemGPT key insight: LLMs can manage their own memory if given \
tools to page information in and out of context" \
-t observation -e concept:memgpt -e concept:self-managed-memory \
--topic "llm-memory-survey"
# Paper 3: "Voyager" (Wang et al.)
remind remember "Voyager stores learned skills as code in a 'skill library'. \
Retrieval matches skills by description similarity. Skills compose and build on \
each other." \
-t observation -e person:wang -e concept:skill-library -e concept:voyager \
--topic "llm-memory-survey"
remind remember "Voyager demonstrates that executable code can serve as a \
memory representation — more precise than natural language for procedural \
knowledge" \
-t observation -e concept:memory-representation -e concept:voyager \
--topic "llm-memory-survey"To auto-ingest raw excerpts instead of hand-picking sentences, pass the same optional --topic so every extracted episode from that ingest gets the tag — still no implicit topic guessing:
cat paper-notes.txt | remind ingest --topic "llm-memory-survey"Consolidation surfaces themes
remind consolidate --forceAfter ingesting several papers, consolidation might produce:
"Current LLM memory systems share a two-tier architecture: fast working memory (context window) + slower persistent storage, differing mainly in how they manage the boundary"
- Confidence: 0.85
- Source: Generative Agents, MemGPT, Voyager
- Relations: generalizes → specific observations about each system
"There is a spectrum of memory representations from natural language (Generative Agents) to structured code (Voyager), with a tradeoff between expressiveness and precision"
- Relations: contradicts → "Natural language is the universal memory format"
"All surveyed systems lack true generalization — they store and retrieve specific memories rather than consolidating into abstract knowledge"
- Confidence: 0.7
- Relations: implies → "Gap in the literature for consolidation-based memory"
Querying across papers
remind recall "how do different systems handle memory retrieval?"
remind recall "memory representation tradeoffs"
remind recall "limitations" --entity concept:memory-architecture
remind recall "retrieval tradeoffs" --topic "llm-memory-survey"
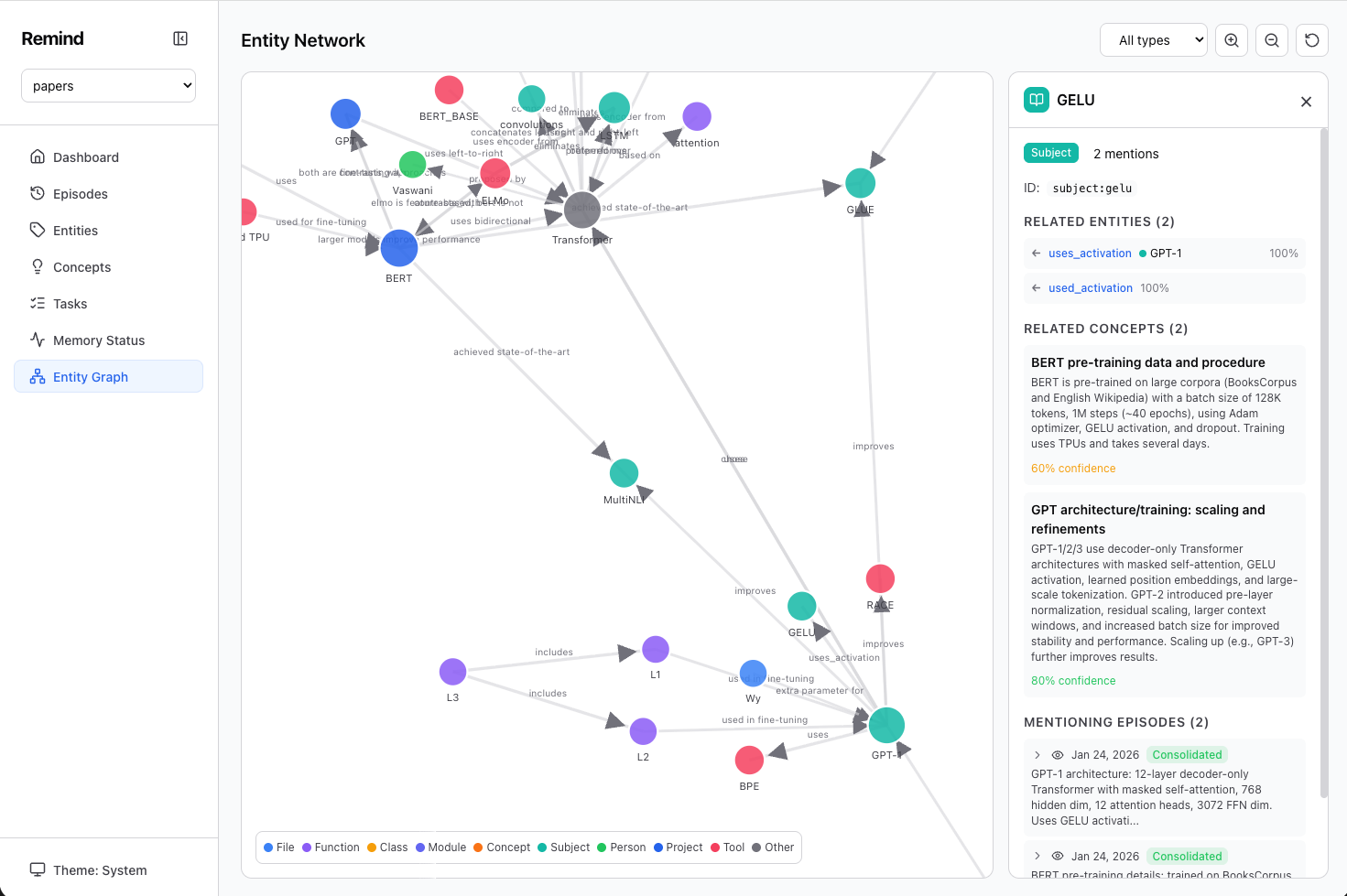
remind entities # See all papers, concepts, and their connectionsThe result
Here's what the entity graph looks like after ingesting several ML papers — concepts, models, techniques, and their relationships, all extracted and linked automatically:
And the concepts view showing generalized knowledge with confidence, conditions, exceptions, and relations:
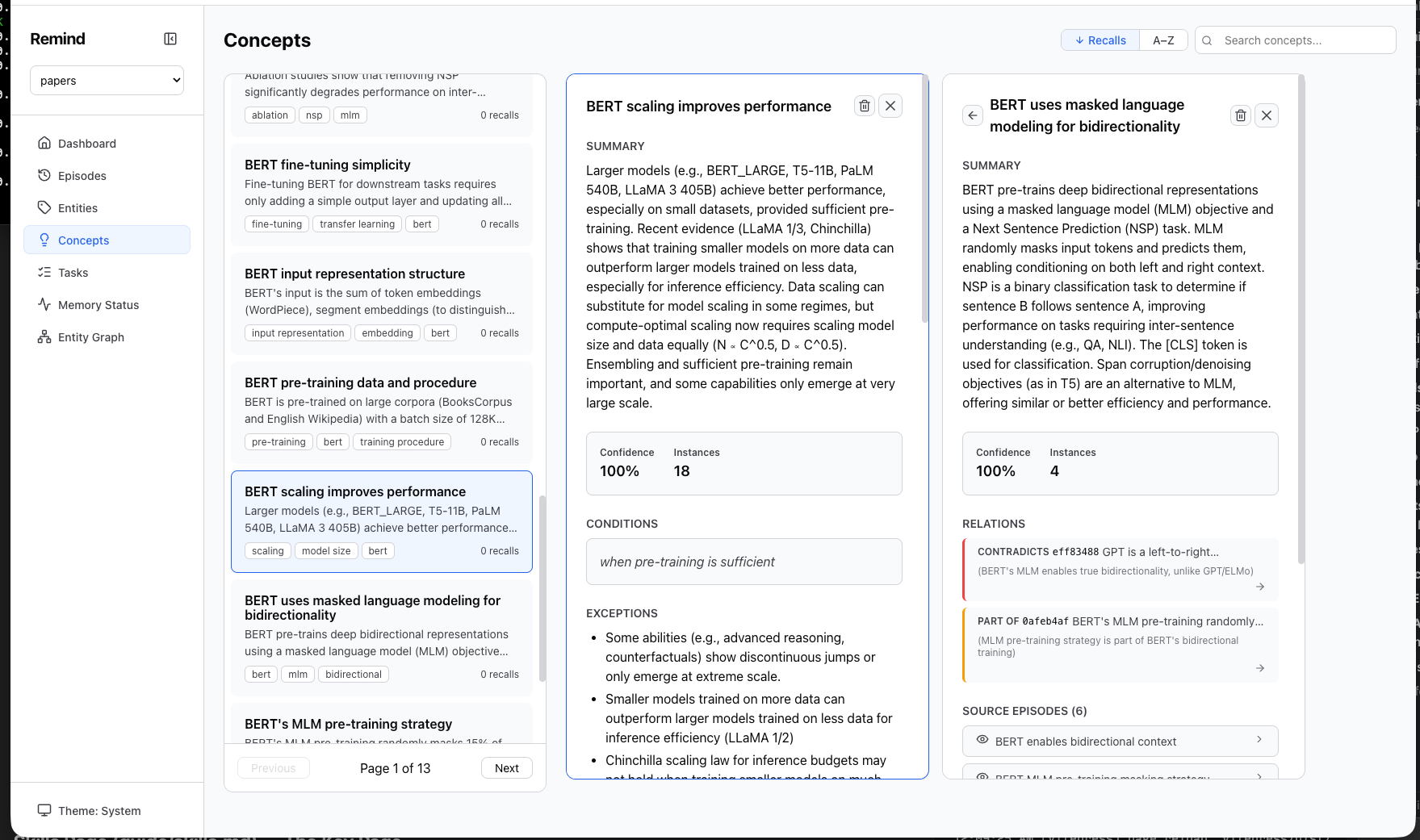
What you get
- Cross-paper synthesis — Themes and patterns that span multiple sources
- Contradiction detection — Where papers disagree, flagged automatically
- Gap identification — What the literature doesn't address
- Entity graph — Navigate from an author to their contributions, from a concept to all papers that discuss it
- Persistent knowledge base — Come back months later and recall the synthesis, not just individual paper notes